{kind=link}
221



In the ever-evolving landscape of big data, efficient and scalable data management is crucial for organizations to harness the full potential of their data lakes. Traditional data lakes often struggle with issues such as data consistency, schema evolution, and performance, which can hinder their effectiveness. Enter Apache Iceberg, an open-source table format designed to address these challenges and revolutionize Lakehouse architectures.
Apache Iceberg is an open-source data table format that helps analyzing large datasets stored in Data Lakehouse architectures. Apache Iceberg was developed by Netflix to overcome the limitations of existing solutions and has since been adopted and contributed to by a growing community. It provides a robust foundation for building scalable, performant, and manageable Lakehouses. The importance of Apache Iceberg in modern data architectures cannot be overstated, as it brings several key advantages that are essential for efficient data management as:
Schema Evolution and Versioning: Unlike traditional data lake solutions, Iceberg supports schema evolution without the need for costly data migrations. This means organizations can add, delete, or rename columns without disrupting existing workflows, making it easier to adapt to changing data requirements.
ACID Compliance: Apache Iceberg brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to data lakes, ensuring data consistency and reliability. This is critical for maintaining data integrity in multi-user environments and for enabling complex data operations such as batch and streaming workloads.
Partitioning and Pruning: Iceberg introduces advanced partitioning strategies that significantly improve query performance. It enables fine-grained partitioning and efficient pruning, allowing queries to scan only the relevant parts of the data, thereby reducing I/O and speeding up processing times.
Time Travel and Snapshots: With Iceberg, users can perform “time travel” queries, accessing data as it existed at a specific point in time. This is invaluable for debugging, auditing, and historical analysis. Snapshots provide a consistent view of the data at various points, facilitating rollback and data recovery.
A Data Lakehouse can be defined as a modern data platform built from a combination of a data lake and a data warehouse. More specifically, a Data Lakehouse takes the flexible storage of unstructured data from a data lake and the management features and tools from data warehouses, then strategically implements them together as a larger system. This integration of two unique tools brings the best of both worlds to users. Let’s combine the best open table format with the best data warehouse!
Let’s take a CSV file which will we convert into iceberg format. For that I’m going to use the Spark service in Oracle Cloud called Data Flow. I had simplified the code from the following link where also I obtained an example CSV file: Downoad Link.
The following Python Spark job will take a CSV and will generate the iceberg format:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql import SQLContext
if __name__ == "__main__":
csvFilePath = sys.argv[1]
icebergTablePath = sys.argv[2]
spark = SparkSession \
.builder \
.appName("Iceberg Simulation") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.dev", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.hadoop.fs.AbstractFileSystem.oci.impl", "com.oracle.bmc.hdfs.Bmc") \
.config("spark.sql.catalog.dev.type", "hadoop") \
.config("spark.sql.catalog.dev.warehouse", icebergTablePath) \
.getOrCreate()
sqlContext = SQLContext(spark.sparkContext)
original_df = spark.read.format("csv").option("header", "true").load(csvFilePath).withColumn("time_stamp", current_timestamp())
original_df.write.format("iceberg").mode("append").saveAsTable("dev.db.icebergTable")
print("CSV to Iceberg Job Done!!!")
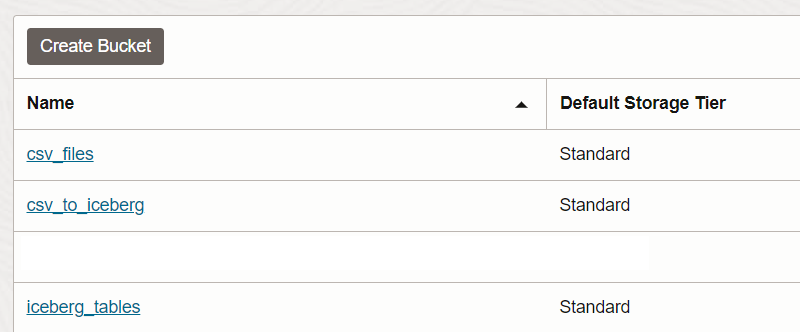
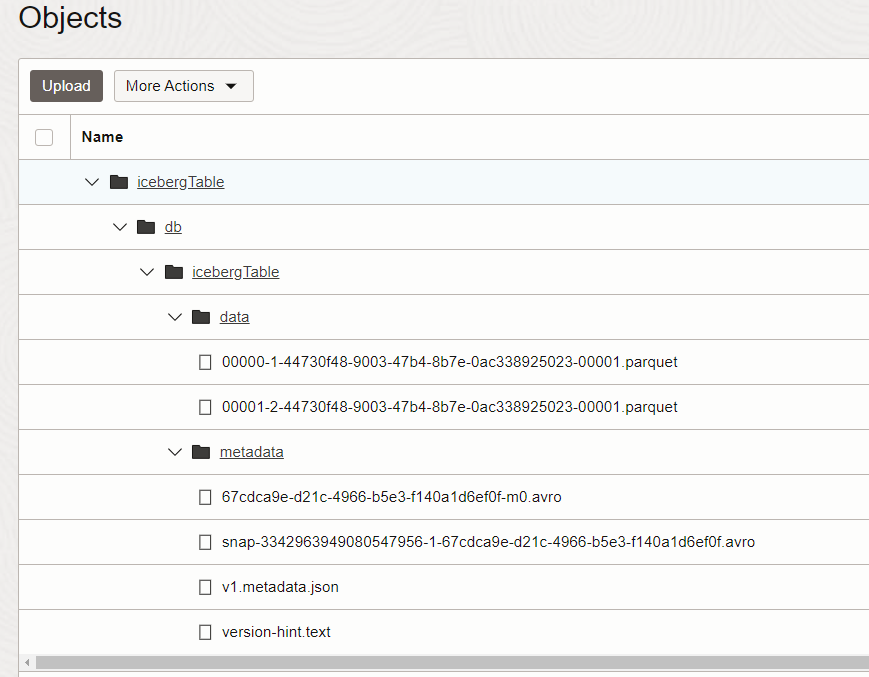
I have created three different buckets in Oracle Object Storage:
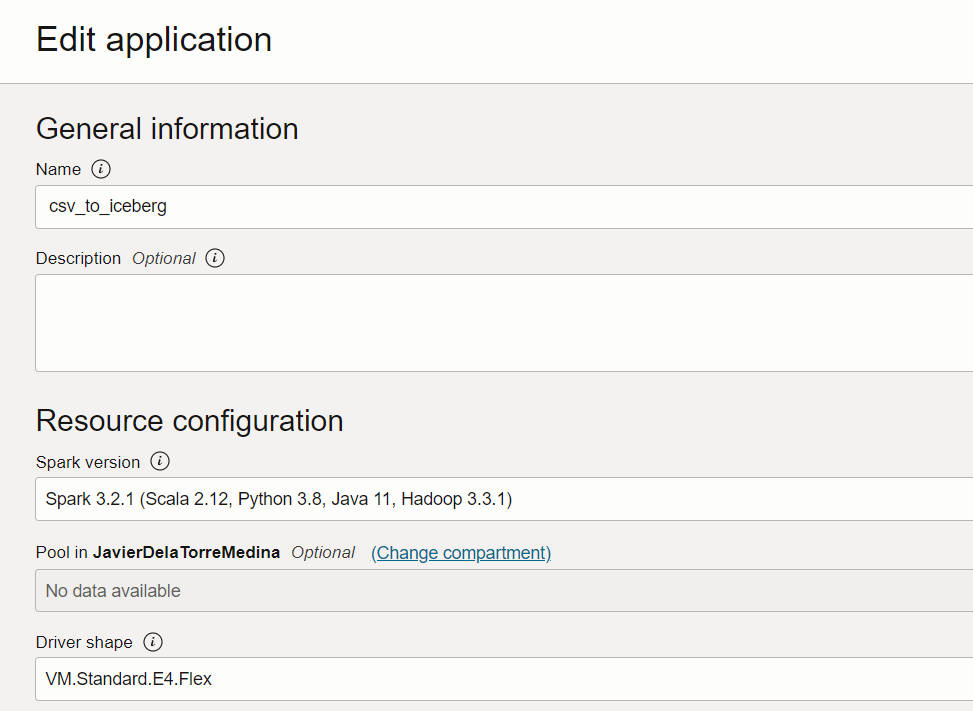
We can proceed with OCI Data Flow. Let’s create a job I called csv_to_iceberg. I will be using Spark 3.2. You can define the CPU and Memory based in the size of your data. I will be using the minimum as it is a small CSV.
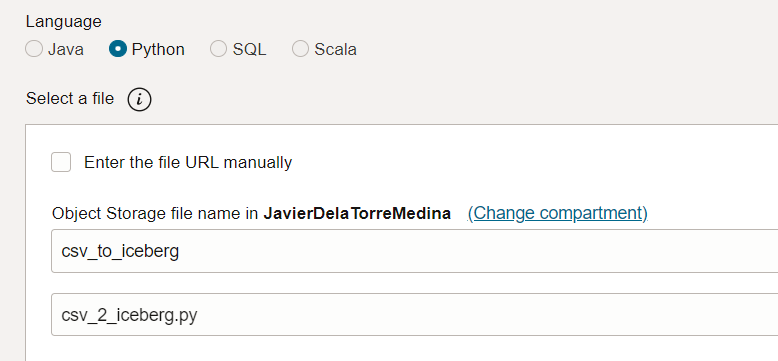
In the OCI Data Flow, I have to define the location of the code. We have to select the Object Storge bucket and the file which has the code.
In our code we have two arguments or parameters: the location of the CSV and the location of the future iceberg table.
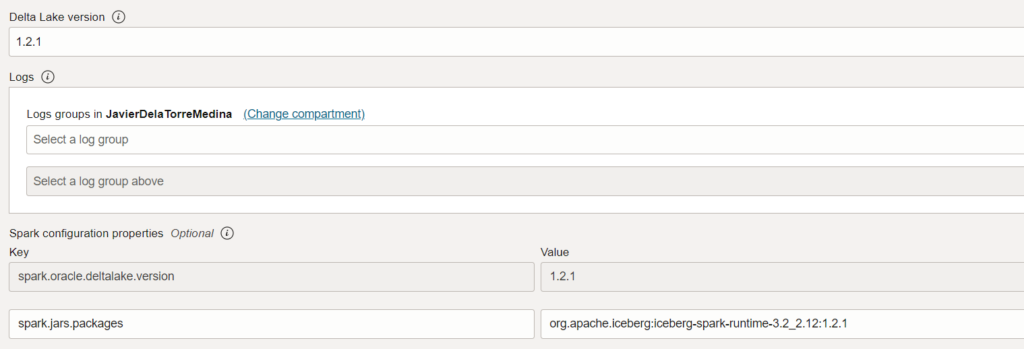
It is very important to add the packages. We are going to define the apache iceberg one. It is important to check the version you are using. You can see we are using Delta Lake version 1.2.1 and Spark 3.2. This is reflected in the package.
Once we have everything defined in the OCI Data Flow job, we can click on run. If we check the Object Storage, we can see the iceberg table is there!
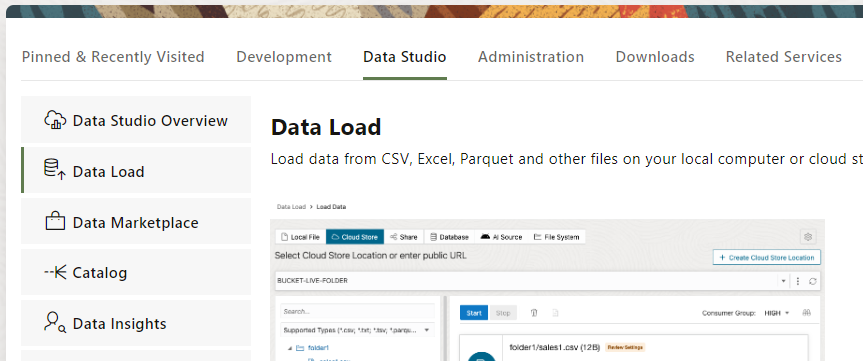
Now is time to read this table! Using the Oracle Autonomous Database, we can consume this table using the Data Studio easily. Go to your Autonomous Database and click on Database Actions. You will have a interface like the following. Select Data Studio and Data Load.
When we click Data Load, we have few options. As we want to read the external data and not loading it inside the Oracle Autonomous Database, click on Link Data.
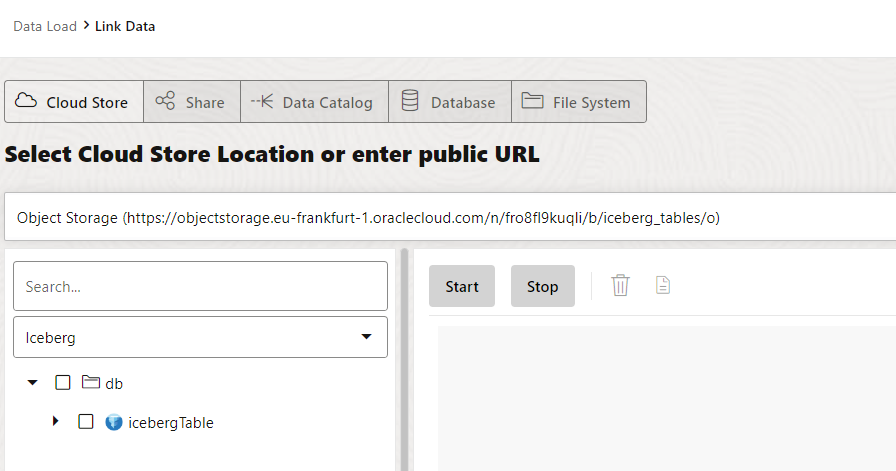
If you select your Cloud Store, and you have already created a location you will be able to see the the iceberg table we crated.
If you don’t have a credential, you can create it via SQL or use the assistant with “Create Cloud Store Location” to define the credential and the bucket you want to read.
begin
dbms_cloud.create_credential (
credential_name => 'OCI_CRED',
username => 'YOUR_OCI_USER',
password => 'OCI_USER_TOKEN'
);
end;
/
To create the external table, you need to drag and drop the icebergTable into the canvas in the right. Then you can click start. This will generate the metadata for reading the table.
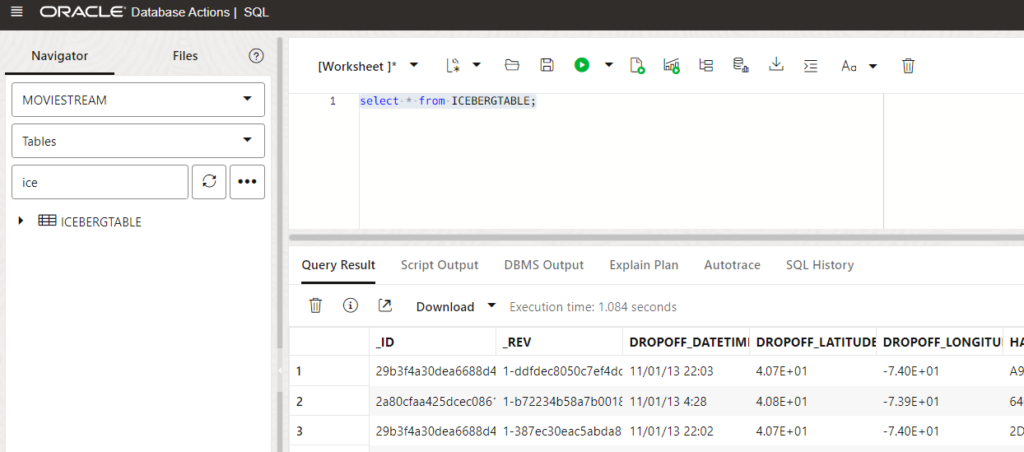
Let’s read the table. We can go to the SQL Developer web and we will see the table is there. We can run SQL over it. Oracle Autonomous Database will read the parquet files from the Object Storage.
In this post I have shown how easy is to read iceberg tables and how easy is to create Data Lakehouse architectures using Autonomous Databases. I recommend you to have a look into the documentation here if you want to understand all the possibilities supported, like for example using AWS Glue Data Catalog.
Happy testing!